
Automating Alpha Pt.2 - Best Practices
Best Practices, Tips, and Tricks For Automating Alpha Discovery

Introduction
In the previous article, we provided a very high level run-through for automated alpha generation. We’ll continue down the path of a Birds Eye view in this article, but the next will be much more code focused. It’s taken a fairly long while because of the heavy focus on code, so hence a later part of the series.
I think a bit of code is useful for getting people experimenting faster, which of course, is the only real way to grasp any of what I tell you to the fullest extent, but it’s hard to convey high-level ideas across code, such as mental frameworks for approaching the challenge itself.
Index
Introduction
Index
Input Data Normalization
Tuning of Selection Likelihoods
Known Strategies as Base Alphas
Too Many Inputs & Unrelated Data
Automated Alpha is Great For Bad Researchers
Breadth Beats Depth
Exponential Temporal Weighting
The Many Outweigh The Few
Wholistic Perspective
Input Data Normalization
It is important to ensure that our data has been properly normalized before we use it as input data for our genetic algorithm. This means that we should ensure that our data is homogenous and comparable. Raw price and financial data are not comparable. From high - low, this would mean that stocks with a larger price on average will have a much larger score. This adds additional noise to the process and makes it harder for us to work with.
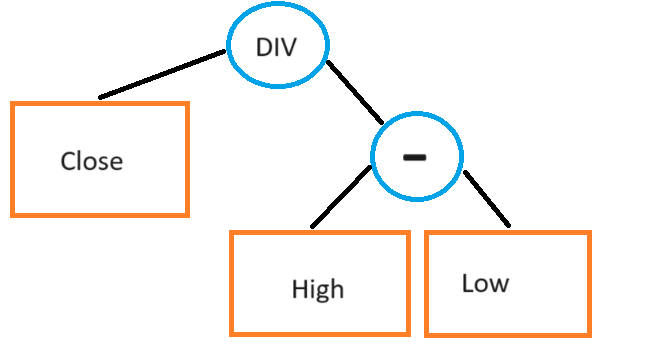
We can choose to only work with returns, but this again limits us by preventing us from using perfectly acceptable formulas such as:
This is fine because we are normalizing it to ensure that our prices do not scale with the overall value of close, which is something we, as the researcher know, is not a place to find any real alpha at all. Thus, we embed this rule to ensure that the algorithm knows it as well.
For financial data, we can adjust with the market capitalization, or simply the price if it is already on a per-share basis.
This leaves us with 4 options:
Unconstrained optimization, and we simply assume that alphas like high - low will evolve into a normalized version of themselves in the algorithm’s attempt to reduce noise.
Forcefully normalize everything, and use close-to-close returns (instead of close) or P/E ratio (instead of profits).
Use normalized-based alphas instead of the raw data. I.e. for High, we turn it into High/VWAP, where VWAP is our chosen normalization variable for all raw price-based input data sources. Under this model, all raw price inputs must be divided by VWAP as it is our normalization variable.
Option 3 is by far the best option here, where we set a default normalization source for every single type of raw data that we have. If we have the equation:
It then becomes:
This is a great solution because the VWAP will eventually factor out if we introduce something like a divide by close to the equation:
Normally, we would have to increase the height of the tree from 2 layers (bottom layer is high and low, top layer is subtract) to 3 layers:

When all we are really doing is normalizing the equation, and not attempting to add any complexity here. However, if we decided to deviate from the default standard normalization metric that all the raw price data inputs have to use (VWAP), and used Close to divide it instead, then we would end up with 3 layers:
Thus, when we are counting the height of the tree, we should ignore it if it meets the following criteria:
Division operation
Denominator is a default normalization variable
All numerators are in the raw input group associated with the denominator’s default normalization variable status
Thus, we can normalize our alphas without penalizing the search process for this normalization, without strictly forcing them into one choice for normalization if it decides it’s worth increasing the complexity.