

Introduction
Building on previous articles in the area of synthetic portfolios, we will explore a convex method for building synthetic portfolios without introducing constraints like sparsity. In future research, we will look at 2 heuristic approaches that allow us to build on these methods and introduce sparsity constraints. In this article, we once again look at the portmanteau criterion as our chosen method for generating non-sparse synthetic portfolios. I won’t dive too much into the theory here since you can read up on that yourself (I’ll butcher it anyways), but I will walk through a code implementation of this. We do not produce any backtests or strategies here, but we do present a tool every quant should have.
Data
We would have a pretty hard time trying to form a robust portfolio using a large number of portfolio constituents. There is a much larger probability of overfitting, and in other cases, this can be impractical for computing reasons. The GEP (generalized eigenvalue problem) framework used to solve this optimization is highly compute efficient but the downside is that it cannot produce a sparse output.
Our universe consists of S&P500 stocks in the form of daily close prices for each asset. We ensure that our universe is part of the S&P500 for 3 main reasons:
Greater ability to trade portfolios in size due to better book depth.
We don’t need short-margin availability datasets as margin is probably available.
Fake mean-reversion from the bid/ask bounce is less pronounced because of tighter spreads.
Starting with the first point, we need to ensure that our portfolios will be able to absorb some decent size without creating a large impact. This is important for many traders as something you can only put $10,000 behind but makes 60% a year is probably not even worth coding up despite the great APR.
The next two concerns are designed to avoid situations where our backtests aren’t realistic for live trading. This is either from assets being unavailable to short or from mistaking the price bouncing between the bid and ask as actual mean reversion. Most bars use the last trade to form the close. If this trade is a buy and in the next candle it is a sell we will see the price change by the size of the bid/ask spread. The actual fair value could have remained unchanged during this period.
To form our portfolios we should select the optimal assets ahead of time. Otherwise, we will not be likely to generate a robust portfolio. In our case, we use the below list of tickers in the electrical utility category. This is an area that can be expanded upon greatly by looking at other categories/themes or even by applying clustering algorithms to form your portfolios.

Minimizing Portmanteau Statistic as a GEP
Formulating our optimization as a generalized eigenvalue problem (GEP), we can greatly reduce the computational complexity and quickly find an optimal solution. If this sounds a bit too complicated you’ll be happy to hear we are basically using PCA.
For background reading, this is one of the best tutorials on the topic:
https://arxiv.org/pdf/1903.11240.pdf
We will be using the portmanteau statistic (more info in the link below) which we have covered in previous articles. This tests for white noise using autocorrelation. As a result of this, you have to specify the number of lags, in our case, we will use 10, but it is generally recommended to go lower for mean-reversion (what we optimize for here), and higher for momentum.
https://en.wikipedia.org/wiki/Ljung%E2%80%93Box_test
We will need to solve the problem:
Modify w (our matrix of weights for each asset) to minimize the portmanteau statistic with lag p. M represents the autocovariance matrix of lag i.
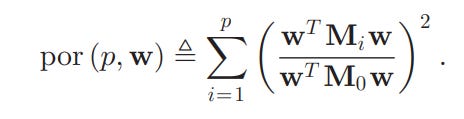
We know p ahead of time and it is a parameter we define ourselves, this is the lag parameter that was mentioned before.
Implementation (Optimization)
The first function we need to define is one that produces our autocovariance matrix. This is done below:
def autocov_matrix_calc(arr, p):
m = arr.shape[0]
arr_demeaned = arr - np.nanmean(arr, axis=0)
return 1 / (m - p - 1) * arr_demeaned[p:].T @ arr_demeaned[:m - p]; Next, we rearrange our optimization problem to produce a matrix we can find the eigenvalues/vectors of:
import pandas as pd;
import numpy as np;
from scipy.linalg import sqrtm;
def portmanteau_gep(df, lags):
df_normalized = df - df.mean(0);
rho = df_normalized.cov().values
rho_inv_sqrt = np.linalg.inv(sqrtm(rho))
pmt_matrix = 0;
for i in range(1, lags):
autocov = autocov_matrix_calc(df.values, i)
pmt_matrix += np.square(rho_inv_sqrt @ autocov @ rho_inv_sqrt)
pmt_matrix /= lags;
eigenvalues, eigenvectors = np.linalg.eig(pmt_matrix)
asc = np.argsort(eigenvalues)
eigenvalues, eigenvectors = eigenvalues[asc], eigenvectors[:, asc]
wgts = rho_inv_sqrt @ eigenvectors
return np.real(eigenvalues), np.real(wgts)The above code goes through the entire optimization logic and is all that you need to test out this model for yourself. We start by de-meaning our data. Then, we take the covariance matrix denoted as rho. After taking the inverse square root of this we can now use it to build our matrix.
This matrix is denoted as “pmt_matrix” and is produced by dot multiplying the inverse square root of our covariance matrix (twice) against the autocovariance matrix and then squaring it. We do this for each lag below our lag parameter.
After that, we divide by the number of lags so that it is an average, not a sum, and then our matrix is finished. The hard part is over now; we can simply take the eigenvalues and eigenvectors of our matrix and we are almost finished.
Finally, we sort our eigenvalues and eigenvectors. Our smallest eigenvalue's corresponding eigenvector can be dot multiplied with the inverse square root of our covariance matrix “rho_inv_sqrt” to give us the weights that minimize our portmanteau statistic. This is the weights for our mean-reverting portfolio. We can do the opposite of this to get a momentum portfolio, although, in my experience momentum portfolios are best formed using other methods and approaches not covered in this article.
Implementation (Generating Portfolios)
Applying this method using a lag parameter of 10 to our training dataset spanning 2017-01-01 to 2018-06-01 we produce this portfolio out of sample:
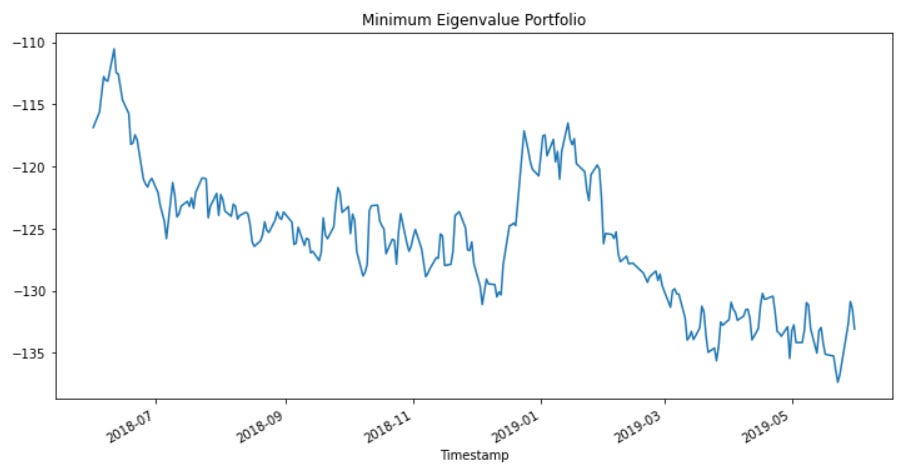
Our above portfolio exhibits high degrees of mean-reversion but has a hard time with stationarity. This metric is best used for short-term mean-reversion strategies so daily data isn’t the most optimal way to use this.
The (not shown) momentum portfolio (maximum eigenvalue) is quite mean-reverting since we used a short lag and portmanteau is best used for mean-reversion.
Conclusion
The main objective for this article was to present GEPs as a foundation for future articles. In the future, we will look at the truncation and greedy methods for adapting this method to sparse portfolios using heuristics that save on compute.
We’ve also managed to present a method for determining the optimal portfolio given a pre-selected group of assets. This is useful for strategies that work by finding groups of assets that are similar. We can use industry categories or more statistical approaches involving clustering or plain simple top z assets with the largest/smallest metric x. Hopefully, this article is useful for readers in search of a new tool they can use when developing strategies in this area.