
Pairs Trading Framework & Process
A full guide on pairs trading and building mean-reverting portfolios

Introduction
As many of you will have seen, recent articles have focused a fair bit on pairs trading methods. After finishing a 3 part series where we went from non-sparse mean-reverting portfolios up to sparse mean-reverting portfolios I thought it was about time to give a proper guide on all the different nuances of pairs trading.
In this article, we will take a different perspective than we normally chose, and cover pairs trading, specifically building mean-reverting portfolios, as a start-to-finish framework. Many statistical arbitrage managers will run these strategies alongside others, and this is by no means an exclusive area to specialize in.
DISCLAIMER: This is going to be quite, if not a lot, anecdotal. It is based on a lot of research into the space, and I even ended up writing a paper on some sparse eigenportfolio math during my adventures. I don’t often work with these strategies anymore since migrating from equities, but I hope to share the knowledge regardless.
Index
This is quite a long article as it is a full guide to pairs trading and all the lessons/anecdotes I’ve accumulated over the years. You’ll be happy to find that there is an index to help organize all of this content:
Introduction
Defining Pairs Trading
Pairs Trading as an Optimization Problem
Robust or Non-Robust: A Temporal Question
The Parameters That Matter
How Data Parameters Drive Modelling Choices
Short-Term High-Turnover Pairs Trading
Long-Term Low-Turnover Pairs Trading
The Different Flavors of Mean Reversion
Optimization Metrics (Mean-Reversion)
Optimization Metrics (Alternative Objectives)
Methods for Optimization
Non-Optimization Focused Approaches
Conclusion
Defining Pairs Trading
I think most readers have a general idea of what pairs trading is, and if you don’t - Google exists, but I want to really dig into the question of what is pairs trading?
For many, it is simply trading the spread between two cointegrated assets, but this is no longer true or an effective definition. Modern pairs trading can involve a variety of assets, with a mix of long and short exposures. They don’t have to be cointegrated or stationary either. You can generally think of pairs trading as the art of generating, trading, and managing portfolios that exhibit both predictability and efficient tradeability. Predictability in this sense refers to the fact that our portfolios follow a (usually mean-reverting) pattern that is robust and stable. This is not to be confused with the VAR(1) (BTCD) approach where predictability means something different.
Where does pairs trading end? This isn’t an easy question either. If I take a KO - PEP spread and decide to only trade one leg, the one I expect to do the moving, am I still pairs trading? I could be capturing 90% of the variance of the equivalent (although hedged) pairs trade but would this still be a pairs trade?
In most cases, the scenario where only one asset will move occurs because one asset is driving all of the variance between the two of them. There is a leader and a lagger. This is a lead-lag trade, one that has many similarities to pairs trading, and with a lot of room to bridge ideas, but is definitely still its own distinct area.
Pairs Trading as an Optimization Problem
Pairs trading in my view is best thought of as an optimization problem. We have 3 primary objectives we need to optimize for:
Predictability (Well Behaved Mean-Reversion)
Trading Costs Relative to Profit (Liquidity, Variance, Notional vs. Net Ratio)
Stability of Statistical Properties (Stationarity - although often this is worth giving up to get a much better deal on parts 1 & 2)
You could very well sit down and create a metric for mean reversion then slap some assets into a neural network and shit out a mean-reverting portfolio. That doesn’t guarantee that your portfolio will be robust, it will likely be overfit in fact, and will decay completely in live testing. Often a healthy dose of heuristic methods and well-thought-out processes will provide the best results with our limited data.
We have already framed it as a problem like this in previous articles. Our SDP article optimized for mean-reversion using a VAR(1) framework (objective 1) and made trading efficient by inducing sparsity and variance constraints (objective 2). It was also convex, which means it had far less ability to overfit, helping us achieve objective 3. An earlier article took a more aggressive stance and used the portmanteau statistic to achieve objective 1, but only implemented some controls on the liquidity requirements of our input universe to help aid objective 2. It was definitely not the most robust technique, but as we will discuss later, robust != optimal for many cases.
Robust or Non-Robust - A Temporal Question
In my view, it was never a question of how can we make our portfolio robust always. Unstable portfolios add cost, but you can still make money if the other objectives get optimized really well. Below is a portfolio that is constructed from two fractional Brownian motion processes. One has a Hurst exponent of 0.3, the other has a Hurst exponent of 0.9. What this means is that the 0.9 Hurst process is our drift (trend) which we do not want, and the 0.3 Hurst process is the mean-reversion (we want this). The trend can be thought of as noise that damages our PNL, but we can still adapt to it. The use of techniques like Bollinger Bands allow us to trade non-stationary spreads, with the error term from non-stationarity as a cost.
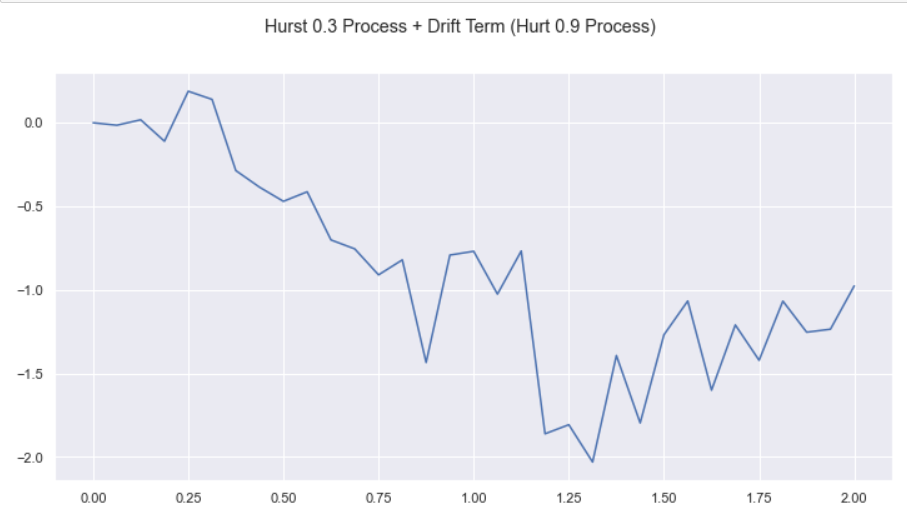
The cause of loss for Bollinger Band based approaches is what I call lag error. I have covered lag error in a thread on my Twitter:
Moving back to the concept of robustness. We cannot have everything, and there is usually a question of what model is right for the job. If you are trading higher frequency timeframes, you need to optimize for trading costs, and you will likely trade short-lasting effects which will quickly disappear. This is fine. We already have a framework that is robust to instability. Instead of non-stationary behavior making it impossible to trade it just acts as a variable cost against our revenue from mean-reversion. More effective spread trading models and optimization for well-behaved mean-reversion lower this cost.
The reason I say this is a temporal problem is that as you increase your timeframe, you have less opportunity to diversify, both in the correlation of your spreads and the law of large numbers with trades. This is partially because correlations increase as the timeframe increases (so you have less ability to form multiple diversified pairs portfolios). The other issue is that you will make fewer trades so the law of large numbers applies less. Above both of these, the key reason why it makes sense to pick more flexible and less robust models for shorter timeframes is because the relationships are more complex and unstable on shorter timeframes. To detect these we use models which fit more but do not create as robust portfolios, in a lot of cases the extra mean reversion we gain outweighs the lag error introduced.
The Parameters That Matter
I wouldn’t say any of these are necessarily parameters as you might normally think of them, but they are under your control. Here is a quick list of the data-related ones:
Universe Size
Data Frequency
Training Period Length
Test Period Length
Validation Period Length / Use
It is important to use the right data. How large should the starting universe you pick from be? Should we filter for liquidity to reduce turnover costs? What about the timeframe - there is a big difference between 5-minute bars and daily bars. You also get to play around with the length of your training, validation, and test sets.
The validation set is an optional extra set you add between the training and testing sets. You might generate 30 portfolios, then for a validation period you measure their ADFs, rank them on ADFs, take the top 3, and trade the top 3 in test. Here we are sacrificing the number of portfolios / “freshness” (much like an apple, portfolios decay quickly, especially when trained on short-term data) for hoped stability.
What about model-related choices we can control? Here’s a quick list:
Portfolio Sparsity
Metrics / Combination To Fit The Task
Optimization Model
There is definitely a “right” set of metrics to get a certain type of mean reversion. This is important and should come inside of the overall situation context. All of these questions are part of this context, but typically our first list is what drives the choices we make in our second list.
Portfolio sparsity isn’t something that greatly affects the mean-reversion of portfolios, a 4-asset portfolio might behave the same as a 6-asset portfolio, but in the long run, the extra cost to trade 2 more assets can add up. It is really a question of inducing sparsity, which is just a branch of the overall objective of reducing turnover costs, but at the cost of the mean-reversion or stability the portfolio exhibits. If assets do not meaningfully contribute to the portfolio there are methods like Truncation contribution to test whether they are noise and exclude them.
How Data Parameters Drive Modelling Choices
The data parameters directly affect how you then model it. This is a pretty basic concept, but we will walk through the 3 different modeling choice subjects and how they are affected by different data. This all reverts to the different focuses you have with different types of pairs trading.
The next two sections will examine short-term high-turnover pairs trading and long-term low-turnover pairs trading to give insights about what are the right choices and what problems should you focus on solving based on your data/timeframe of effect.
Short-Term High-Turnover Pairs Trading
With short-term high-turnover pairs trading:
Transaction costs are important and thus we care a lot about:
Spread
Exchange Fees
Sparsity (2 legs is easier to limit fill than 10)
Volatility (larger moves, easier to beat costs)
Notional vs. net exposure ratio (If I have to spend $1000 notional to buy a $100 net exposure portfolio that is effectively a 10x multiplier on trading costs as most of the exposure I buy cancels out). Called SNVR (standardized notional volume ratio when we adjust for volatility, otherwise it is just NVR).
Mean reversion effects are far stronger.
Effects are generally less robust.
Fleeting / more complex relationships require more fitting.
More data to work with.
Less information per data point (this combines with the above point to create larger train/test datasets in terms of data points).
Low correlation between different pairs portfolios.
Higher Sharpe / reward → much harder. A high turnover means you are temporally diversified. If you make 1000s of trades they will average out and your risk will be lower, this is boosted by low correlations. This means the reward is larger compared to long-term methods, but that slight edge per trade is competitive.
The implication of some of these is quite substantial. If you know that finding highly mean-reverting portfolios is easier, then you are fine paying some of that away as lag error and using bolling bands / dynamic mean based methods of capturing the mean-reversion. If your mean-reversion is weaker (like long term) you need to focus on robustness because you cannot afford to pay for the lag error of a non-robust portfolio.
There is huge importance in trading costs and optimizing that. How many elements should your portfolio contain? Can we use limit orders to execute? You might have 6 assets, but if 1 asset is 40% of the portfolio it is perhaps worthwhile trying to get that leg in as a limit order, but not always.
Think of short-term high-turnover pairs trading as the following equations:

The average move captured puts volatility, but also our ability to capture it (lag error) at the front of the equation. We then think of mean-reversion strength & quality as the probability of this being in our favor and multiply as such. Trading costs are subtracted net of all this.
Long-Term Low-Turnover Pairs Trading
With long-term low-turnover pairs trading:
Low turnover means transaction costs matter far less
Mean reversion tends to be weaker, but more robust
Risk premium / generally easier to make money in
Fewer data points to work with so requires less fitting
Portfolios tend to be correlated / diversification is harder
News can affect prices more, creating tail risk
As with longer-term strategies in general it is easier to make a little bit of money, but many many times harder to make a lot of money in a low-risk manner. The weaker mean-reversion strength also means that methods like stochastic control are not suitable to trade the spread as they will fail to fit properly.
It is important to understand the nature of these effects and that they are different when looking at the short-term and the long-term. The best way to think of it in my view is that with long-term effects you are focusing on collecting a small risk premium each time and not taking downside. For short-term pairs trading it is the other way around. Your default starting point is losing small amounts of money because of transaction costs. Once you cross that threshold of beating fees your profit rockets.
Longer-term strategies tend to have fewer data points to work with and there is less time for losses to average out, not to mention the fact that portfolios have higher correlations killing diversification. This all culminates to require the use of simpler models when generating long-term portfolios and focusing on how can we keep these portfolios stable. When each trade matters / has a larger impact on the final PNL you need to focus on improving quality since you cannot rely on quantity / averaging out.
The Flavors of Mean Reversion
Ideal mean reversion should have minimal lag error. This means it should have one single frequency and stable properties.
What do we mean by frequency? This is where fractal methods like Hurst can come in handy. More intuitively, “how does price cluster around different price levels?”, and “how many levels are there?”. If our process has 3 states, up, down, and at mean if it is only able to be in one of those 3 states and the prices for those states are constant we get a portfolio like this:
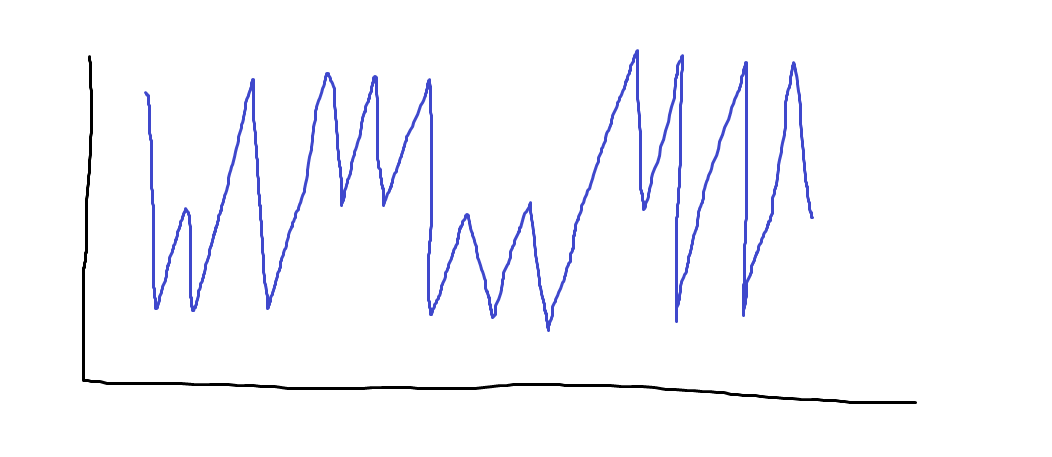
The above chart clearly only has 3 prices it ever visits.
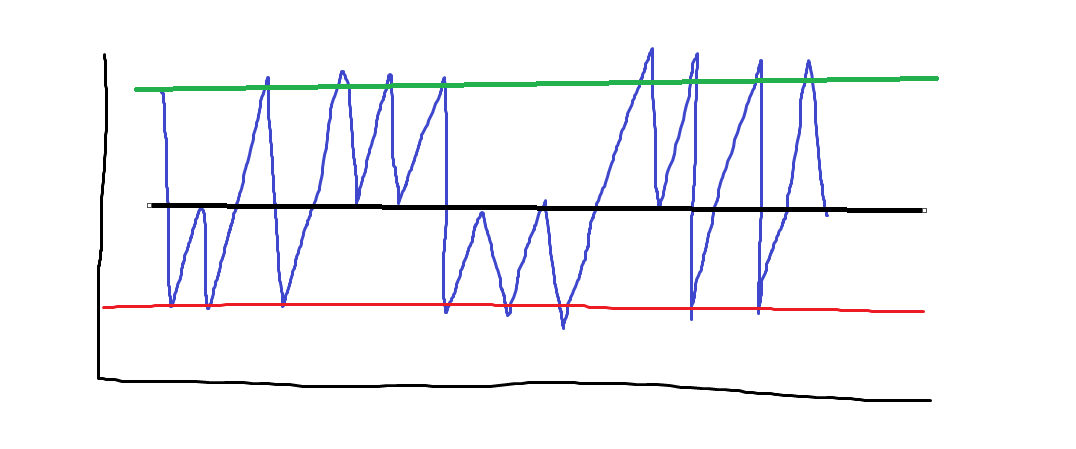
Since we have no lag error we can capture these moves really well. If the price is at our upper band we have close to 1 probability that the price will then go down. In normal settings, however, the probability curve does not look like this.
The different frequencies that mean reversion or generally cyclical behavior occur on primarily influence how we trade the spread.

This is an example of a mean-reverting process with 2 different frequencies. We either capture the short-period mean reversion or the longer-period mean reversion, but each will work against us.
If we capture the longer period we will just have all this extra mean-reversion add noise to our PNL curve. If we are capturing the short period, one of our bands will be more likely to get hit because of the longer period reversion and that will introduce a large degree of lag error.
This is not really an issue for longer-term pairs trading as portfolios tend to exhibit simpler mean-reversion. Whether this is a fundamental nature of mean-reversion on this timescale or a reflection of the fact that our models must be simpler I can’t say, but either argument would be valid.
For short-term pairs portfolios, there is definitely an issue with multi-fractal mean reversion. Models have far more data and tend to be able to fit more making this a common type of mean-reversion to encounter.
Mean reversion may also be thought of in the context of white noise or stationarity, but this is a topic with plenty of literature to dig through so I will leave this to the reader.
Finally, I will list some metrics to classify mean reversion:
Half-Life (speed of mean-reversion)
Crossing Statistic (how many times it crosses the mean)
Volatility (self-explanatory)
Kurtosis (We want bounded mean-reversion, not infrequent mega deviations)
Quantile Ratios (Absolute the z-scores, then calculate quantiles, compare the ratio of different quantiles, maybe 95% vs. 99%, is the difference large, this acts as a more fine-tuned version of kurtosis when controlling tails)
Stationarity (non-stationary white noise is a whole different ballpark than standard ADF-created portfolios)
Drift Term (directly looking at drift / change in price instead of stationarity)
Information discreteness of smoothed process (after smoothing, i.e. removing the noise/ mean-reversion, what is the % of data points that had a positive % change vs % of data points with a negative % change? This tells us whether it is non-stationary with a constant smooth drift or if it is all over the place).
Optimization Metrics (Mean-Reversion)
We’ve already given some metrics which classify the behavior of mean-reversion and are some custom metrics I developed whilst working on pairs trading years ago, but here I’ll list through some metrics for mean-reversion that are stand-alone. The previous list was metrics that help you assess the quality of mean-reversion, but most of them still don’t optimize for mean-reversion directly, only the qualities we would want to see if we had mean-reversion. Hence, most of these optimizations are multi-objective.
This is by no means a complete list and should only serve as inspiration. The key is to focus on how these methods work and understand what we are actually capturing.
ADF
KPSS
Portmanteau
Hurst
Crossing Statistic
AR-HMM (similar idea as BTCD, Levendovszky & Sipos wrote the literature here)
Zivot Andrews
BTCD - Box Tiao Canonical Decomposition (also called Variance Ratio or VAR(1))
Kanaya, 2011
Delft et al, 2017
Basu et al, 2009
Delft and Eichler, 2018
Vogt & Dette, 2015
There is existing literature finding semi-definite relaxations for a lot of these metrics so that we can optimize for them in a non-sparse manner before using greedy search to make it sparse, but some of them do not have such relaxations published. One such example is the Hurst exponent, which is a shame because it performs so well once relaxed. Pick up a copy of Boyd’s Convex Optimization and work through it yourself, it isn’t too hard if you have the background down.
Mean reversion strength and robustness are often 2 different tests. In my experience, it is always the tests like Portmanteau which scarcely produce stationarity but also perform the best. You just need to control for stationarity/robustness of the portfolio after the fact in a validation set.
Here is an example with the use of a validation set:
Train 30 portfolios using portmanteau as your objective (train set is 2x as long as test), then for a period equal in length to our test set we wait and watch the portfolios, we then rank them all on their ADF scores or some stationarity metric, and then take the top 3. We run these 3 live in our test set.
Our validation set created a trade-off where we were able to reduce the chance of overfitting by having a period where portfolios could decay after being trained and then can be thrown out before actually trading them. We also improve stability by picking the most stationary portfolios. This comes at the cost of information decay. Instead of being run right after training, when the optimization is most relevant, we had to wait for the validation set meaning that some good portfolios potentially lost mean-reversion strength. For me, the validation set was a great choice in most cases that I worked on, but I would only use it for short-term pairs trading where mean-reversion comes first and stationarity comes second. Longer term you cannot afford to wait because this is a timespan of multiple months, you wouldn’t want to trade a portfolio trained over a year ago.
Optimization Metrics (Alternative Objectives)
We have already listed quite a few alternative metrics under the area of quality of mean-reversion so the remaining metrics focus on transaction costs/practicality.
Our goal is to reduce the amount of notional needed to get a net exposure as this increases costs. If I need 10x net in terms of notional volume to capture a 10% move in the spread, I am effectively paying 10x fees. If I need 3x the net exposure in terms of notional then I have less than 1/3 the cost if I was to capture the same move.
I won’t go ahead and list them all as they are pretty self-explanatory, but you should focus on what drives costs. This should also be a part of the execution. If it is 1 asset long against 3 others short then you can probably execute that 1 asset as a limit order / using actual smart execution where you have some time to execute the order. If it was 3 vs 3 then you have executed 16.5% of the portfolio if you fill one, but if this is 3v1 and you execute the 1 then you have nailed 50% of the portfolio in one fill. If there are 4 orders you get quite a complicated problem of unhedged exposures whilst some legs have been filled. This is another complex problem to solve, one that is rewarded with alpha.
There is also a significant literature on optimization for leverage / budget constraints as well as other real-world constraints that users will deal with for optimizing a full suite of pairs trading portfolios. Literature on this is included at the end.
Methods For Optimization
There are many methods to optimize your portfolio. I will list some of them, specifically the ones I have tended to look at, but will probably ignore others. Do your own research here, but note that the right model will not make you any alpha, but the wrong model will sure as shit prevent you from finding it.
LASSO (brute force)
Simulated Annealing (Dual annealing is better)
Basinhopping (I prefer this to the one above / they are very similar)
Greedy
Truncation
SDP (Semi-Definite Programming)
Non-sparse solving as GEP (used in methods like Greedy / Truncation as a sub-problem)
Feed Forward Neural Networks (They don’t work, but I will give them the mention)
Cyclical Coordinate Descent
Other Brute Force-Based Approaches
DSPCA (SDP is an extension of this)
DC-PCA (difference of convex functions algorithm, DCA)
Relevant literature can be found at the end.
Non-Optimization Focused Approaches
We have tackled pairs trading within the framework of optimization, but there are other ways to think of it as well. I prefer thinking of it as a robust optimization challenge and have found a lot of success this way, but there are also approaches that model the relationships between assets instead of optimizing for a final goal.
The primary approach here is copulas, which can be extended into higher dimensions with vine copulas. This is an approach that performs well and should not be discounted, but it is not something we will dive too deep into.
There are also models which use graphs, but those lean more into the lead-lag literature where we model it as a network.
Optimization methods still play a key role in these as we need to identify our starting universe. This is often done by creating a portfolio using the greedy method and then fitting a copula / vine copula / whatever you want to model to the constituents.
Additional Areas of Study
We have not covered the trading of the spread, universe selection, or regime shift models (the existing literature sucks, just ask yourself “is this portfolio different enough OOS compared to IS that I actually care.” If the mean reversion is slightly lower but it is still stable then it is fine, if the mean reversion is gone and it is unstable then it is useless. There is no need to use a fancy HMM model, a simple metric should serve as an easy proxy).
Universe selection is also an extensive topic and as we saw in the last articles it certainly plays a role in the final output. This can be done by grouping based on industry, or using a simple method to optimize for some metric (maybe average correlation between assets, can significantly speed up this process by taking the eigenportfolios and using the correlation vs the main eigenportfolios instead of pairwise, this reduces noise / overfitting and makes compute faster - I’d still use greedy alongside this though).
There are also machine learning-based methods to universe selection like clustering algorithms (HDBSCAN / DBSCAN is the go-to as K-means produces groups that tend to look like a Voronoi diagram), but at the end of the day the metrics you cluster by are still the most important part.
Conclusion
I hope to end on the note that finding alpha is hard. I gave a list of custom metrics I developed over my time, but to find your own alpha you need to take the same route of understanding these effects and how they behave. How can I isolate effects that improve performance and then capture them without hurting other objectives?
We also didn’t dive much into the problem of trading spreads as this is a whole article on its own.
This should serve as a complete introduction to creating portfolios for pairs trading, I’ll leave it up to the reader to form their own ideas on how to then trade these portfolios as well as come up with novel modifications (coming from an area of understanding/observation of the effects) to find new alpha.
If you enjoyed the post consider subscribing! There are also a few articles I’ve previously written that take a more practical dive into different methods so feel free to check them out.
Literature
“Three l1 based nonconvex methods in constructing sparse mean reverting portfolios”
“Mean-Reverting Portfolio With Budget Constraint”
“Efficient computation of mean reverting portfolios using cyclical coordinate descent”
“A Novel Optimization Approach to Sparse Mean-Reverting Portfolios”
“Optimizing a portfolio of mean-reverting assets with transaction costs via a feedforward neural network”
“Constructing sparse and fast mean reverting portfolios”
“Optimizing Sparse Mean Reverting Portfolios with AR-HMMs in the Presence of Secondary Effects”
“Parallel Optimization of Sparse Portfolios with AR-HMMs”
“Optimal Mean-Reverting Portfolio With Leverage Constraint for Statistical Arbitrage in Finance”
“Sparse mean-reverting portfolios via penalized likelihood optimization”
“Sparse, mean reverting portfolio selection using simulated annealing”
“Developing a fully automated algo-trading system”
“Optimizing sparse mean reverting portfolios”
“A Penalty Decomposition Algorithm with Greedy Improvement for Mean-Reverting Portfolios with Sparsity and Volatility Constraints”
“A simplified approach to parameter estimation and selection of sparse, mean reverting portfolios”
“Mean-Reverting Portfolio Design via Majorization-Minimization Method”
“Identifying Small Mean Reverting Portfolios”
“POLYNOMIAL TIME HEURISTIC OPTIMIZATION METHODS APPLIED TO PROBLEMS IN COMPUTATIONAL FINANCE”
“Detection of mean-reverting phenomenon from American stocks with unsupervised techniques”
“Trading sparse, mean reverting portfolios using VAR(1) and LSTM prediction”
“Solving Mixed Integer Programs Using Neural Networks”
“Mean Reversion with a Variance Threshold”
“Mean-Reverting Portfolios Tradeoffs between Sparsity and Volatility”
“An Intelligent Model for Pairs Trading Using Genetic Algorithms”
“An Advanced Optimization Approach for Long-Short Pairs Trading Strategy Based on Correlation Coefficients and Bollinger Bands”
“Discovery of multi-spread portfolio strategies for weakly-cointegrated instruments using boosting-based optimization”
“Evolutionary multi-objective optimization for multivariate pairs trading”
“Multi-asset pair-trading strategy: A statistical learning approach”
“M of a kind: A Multivariate Approach at Pairs Trading”
“Statistical arbitrage in the US equities market”
“OPTIMAL PORTFOLIO DESIGN FOR STATISTICAL ARBITRAGE IN FINANCE”
“Multivariate Pair Trading by Volatility & Model Adaption Trade-of”