
Why is my backtest wrong?!
Every way you could've messed up compiled into one article

Introduction
It’s a rite of passage in the quant world to fuck up your first backtest. I remember a particularly good backtest early on in my career that promptly sent me to the Lamborghini dealership website to size up which model I would soon be buying. Spoiler! This strategy did not buy me a Lamborghini.
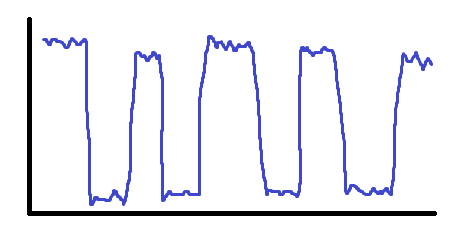
In this specific case, I had messed up the timestamps on my data collection so data from the future was randomly stitched with current data, creating some too good to be true mean-reversion. It looked a little bit like this:
Which was really just two series (with the gaps filled in using red/green) that had stitched together poorly in my data scraper:
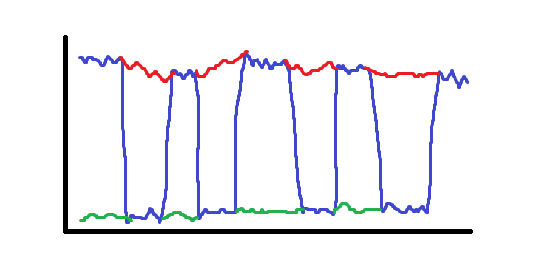
That was a fun lesson, and one I would learn many more times after. If your reaction upon seeing an amazing backtest isn’t “ah man what broke” then you haven’t seen enough of them to know better. There is no exception to this. Every entirely straight line I have ever generated in backtest has had some flaw, and the only super straight lines that actually realized in production weren’t backtest-able in the first place (market making). I’ve certainly had backtests that looked good and turned out to be good, but they never looked so good it was unbelievable - I certainly didn’t google any Lambos.
In the article today, I am going to dive into 20 different ways you can ruin your backtest. This isn’t so much meant to be a Wikipedia article on what overfitting is, since I’m sure you can find that easily, but more an example of many issues and caveats I’ve had to deal with throughout my career so that you can also be aware of them too.
Index
Lookahead
Overfitting
Survivorship Bias
Fees
Spread
Market Impact
Latency Assumptions
Limit Order Assumptions
Adversity Assumptions
Short Borrow
Funding Rates
Withdrawal Issues
Broken API
Assumed Infinite / Free Leverage
Tick Size Issues
Ignoring Gaming Dynamics
Assumed Trading Price is Trade-Able
Trade Price Bid/Ask Bounce
OTC Trades on Main Feed
Wash Flow
Lookahead
This is by far the most common cause of bad backtests. I’ll walk through some key ways that this can happen:
Some smoothing algorithms like Savitzky–Golay actually have lookahead inherent to their logic so whenever you are using a niche smoothing method, just make sure of this - it’s a mistake I’ve made before and it’s cost me a load of time figuring out what happened:

Another common way to introduce lookahead bias is when resampling. We will look below at the default version of pd.DataFrame.resample() compared to the correct way to do it:
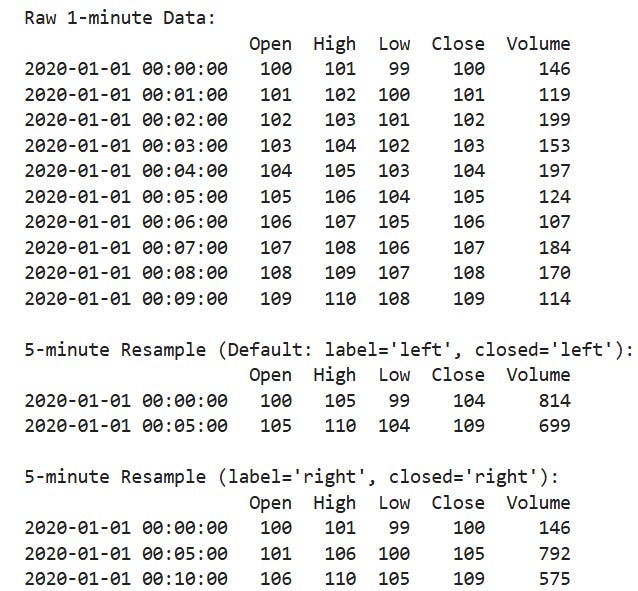
If you use resample with the default arguments (Default: label=’left’, closed=’left’) then you get the example shown above which contains lookahead. We see that the high of 105 occurs at 04 but the timestamp is 05 — thus we have lookahead. When doing resample, always pass in the arguments label=’right’ and closed=’right’. Otherwise your timestamps will be at the open of the bar, which can easily lead to lookahead bias occurring, especially after merging dataframes.
There are about a trillion different ways that lookahead bias can occur and it usually produces a very strong effect in your data, so it’s the most likely answer when you have a really good PnL curve. The only other error that will make a curve look insanely good (completely straight line) is execution based assumptions that are wildly off such as limit fills + rebate + zero adversity + instant fill.
Overfitting
Overfitting is also fairly common. People like to tweak parameters until they eventually find something and a lot of the advice related to avoiding overfitting is fairly sensible. Always keep some data spare that you haven’t tested on. Whether that’s some newer data, a load of other assets, ideally both even, and then right at the end you can validate on this and if it fails you’ve used it and you call it a day. You need some piece of data ideally that you don’t play around with until the end.
Slowly increasing the amount of data you use until you are done the analysis helps. Visually, inspecting the backtest helps a lot as well. You can tell by how smooth the PnL curve is and how many trades were taken whether a curve has a high level of robustness. If all the PnL was made in 3 large jumps and it was flat otherwise then that means we have 3 events that made all our PnL. 3 isn’t many… You can have lots of trades and very few events that make the money, which can still happen in working strategies, positive skewness is a thing afterall, but it means you need to down-weight your mental view of how confident you are in this strategies ability to perform OOS (out of sample).
Double check out of sample very aggressively with not just one but 2 out of sample sets (validation set) when working with machine learning models because even after you fit it, you’ll do hyperparameter tuning.
On the subject of parameter tuning, if you make small-ish changes in your parameters and the overall trend of the curve flips completely then your alpha isn’t likely to be robust. You may see performance change a bit, but for great alphas the signal will shine through regardless of exact parameter choices. I.e. you can be very dirty on the machine learning, portfolio construction, and parameterization components and it’ll still make money.
Survivorship Bias
This is one that is not always worth preventing. Yes, you can use a dynamic universe, but guess what? That’s complicated and a real pain in the ass to code up. At some point you have to say — maybe I’ll only fix this one where it makes sense. If you have a fancy backtester then this makes sense to have in there, but if it’s a one off simulation, then I’m not sure this one always is worth the extra effort.
If you are doing long only momentum, best believe you will be bringing out that dynamic trading universe because survivorship bias will genuinely ruin your results.
If you are on the other hand doing a super delta neutral strategy or one that is directional but with equal long to short exposure over it’s history (which is much easier to check for than coding up a dynamic universe) then it’s worth skipping. I have very rarely had issues with survivorship bias.
It’s not an extremely strong force either so if you are working with 2 years of data and trying to find 3 Sharpe strategies, it isn’t going to be the thing ruining your backtest.
If you are doing 40 year backtests for heavily long strategies then this can destroy you backtest and rip the results to bits. It entirely depends on what you are simulating and whether we are doing it on long enough time horizons where it can make up a very large part of the total PnL at the end.
General tips here:
If you are direction neutral you can skip it
Affects longer term strategies more